The pendulum on a cart¶
Description¶
The environment simulates the behavior of an inverted pendulum. The theoretical system with its equations are as described in Barto et al. (1983):
- A cart of mass \(M\) that can move horizontally;
- A pole of mass \(m\) and length \(l\) attached to the cart, with \(\theta\) in \([0, -\pi]\) for the lefthand plane, and \([0, \pi]\) for the righthand side. We are supposing that the cart is moving on a rail and the pole can go under it.

The goal of the agent is to balance the pole above its supporting cart (\(\theta=0\)), by displacing the cart left or right - thus, 2 actions are possible. To do so, the environment communicates to the agent:
- A vector (position, speed, angle, angular speed);
- The reward associated to the action chosen by the agent.
Results¶
In a terminal windown go to the folder examples/pendulum. The example can then be run with
python run_pendulum.py
Here are the outputs of the agent after respectively 20 and 70 learning epochs, with 1000 steps in each. We clearly see the final success of the agent in controlling the inverted pendulum.
Note: a MP4 is generated every PERIOD_BTW_SUMMARY_PERFS epochs and you need the [FFmpeg](https://www.ffmpeg.org/) library to do so. If you do not want to install this library or to generate the videos, just set PERIOD_BTW_SUMMARY_PERFS = -1.
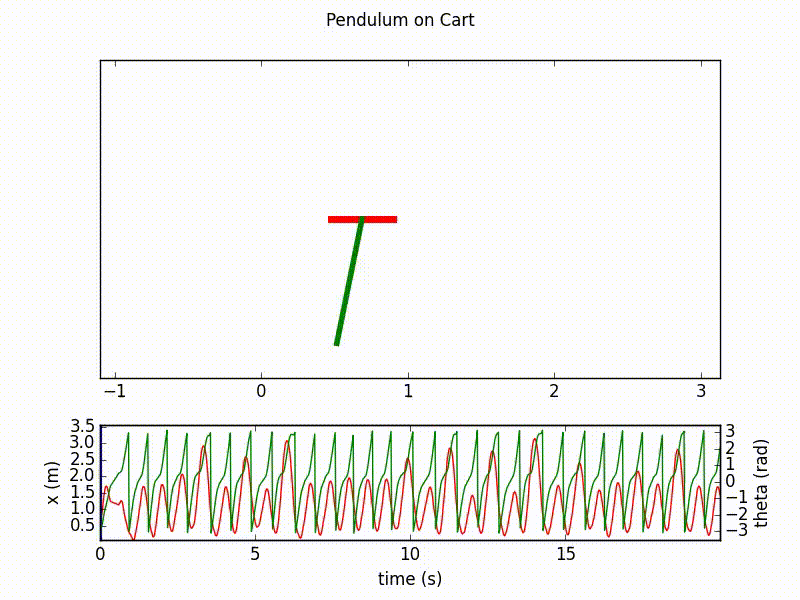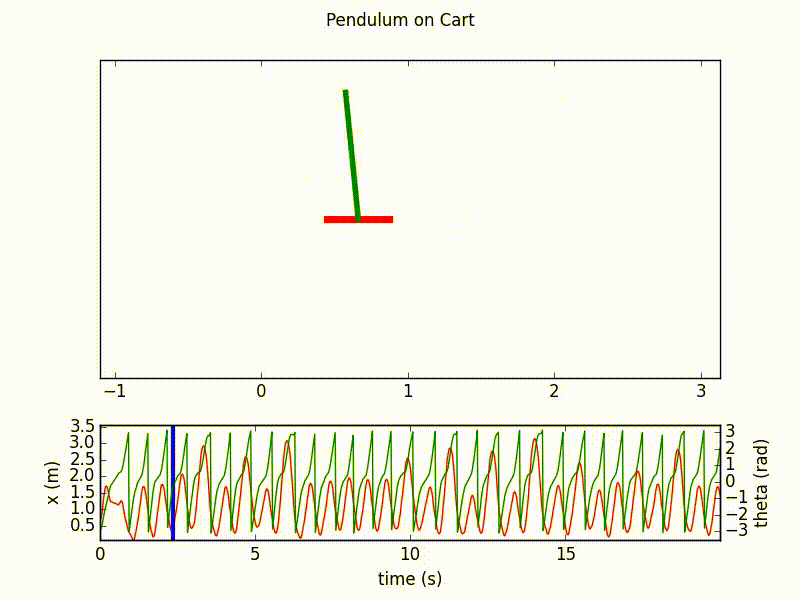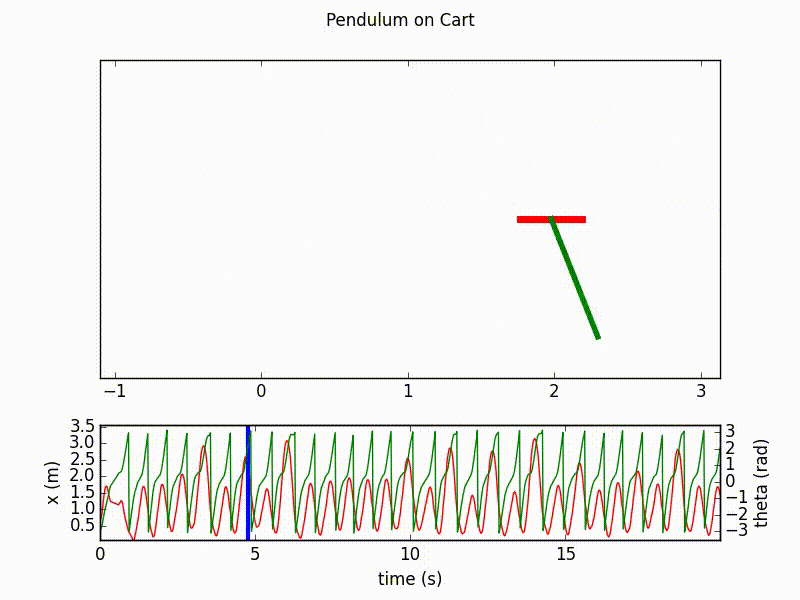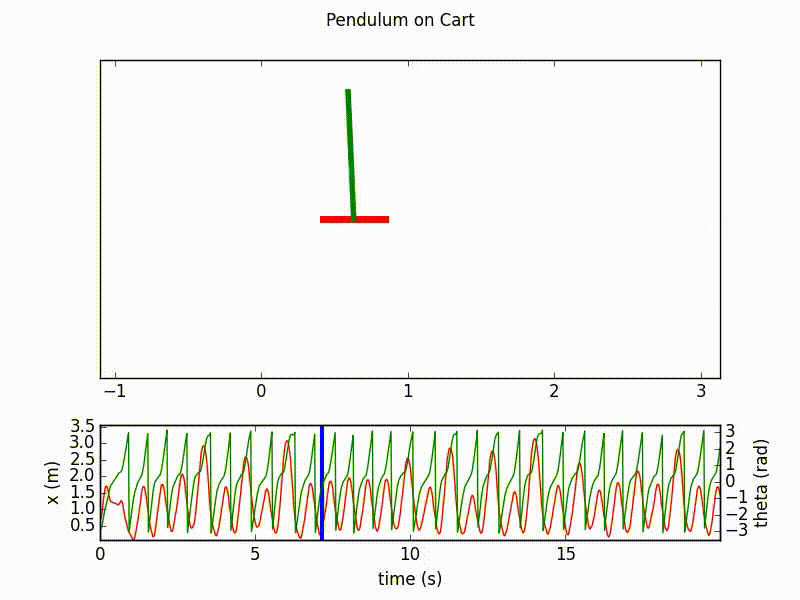
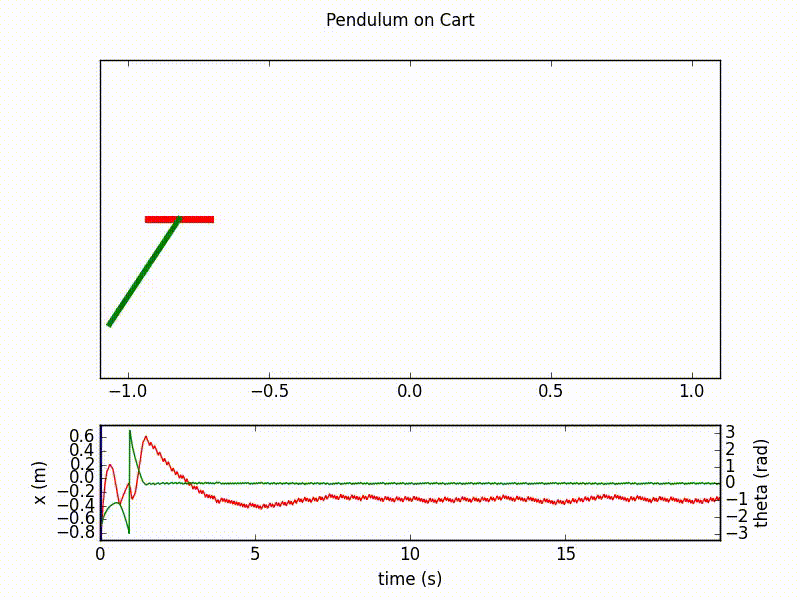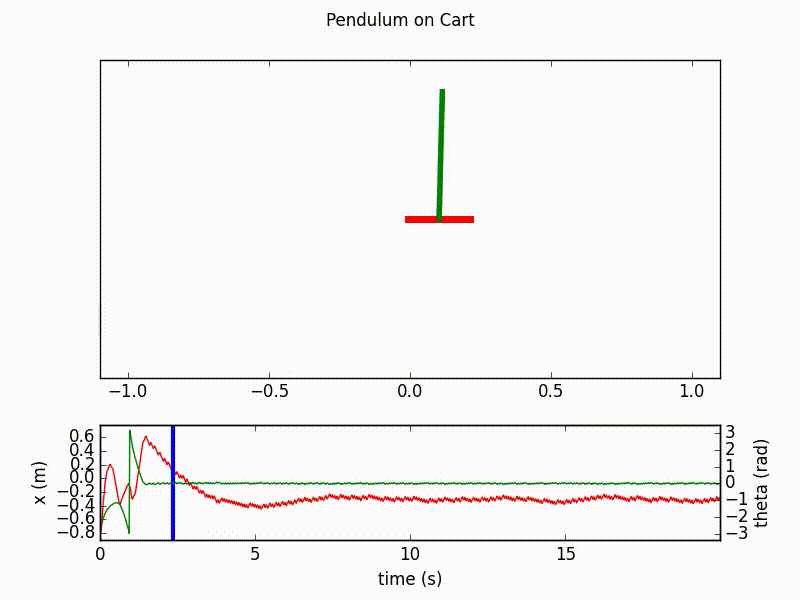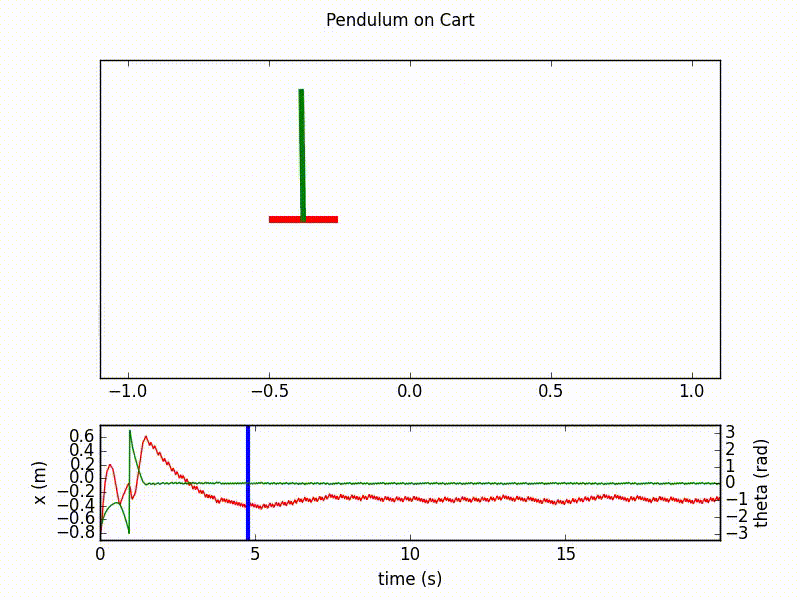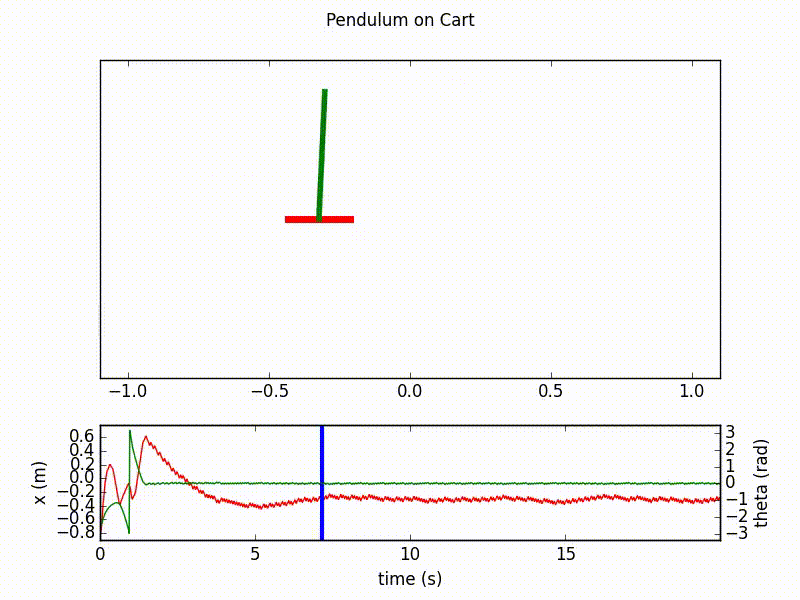
Details on the implementation¶
The main focus in the environment is to implement act(self, action) which specifies how the cart-pole system behaves in response to an input action. So first, we transcript the physical laws that rule the motion of the pole and the cart. The simulation timestep of the agent is \(\Delta_t=0.02\) second. But we discretize this value even further in act(self, action), in order to obtain dynamics that are closer to the exact differential equations. Secondly, we chose the reward function as the sum of :
- \(- |\theta|\) such that the agent receives 0 when the pole is standing up, and a negative reward proportional to the angle otherwise.
- \(- \frac{|x|}{2}\) such that the agent receives a negative reward when it is far from \(x=0\).